as published in HPCwire.
It was established right out of the starting gate: AMD’s Data Center and AI Technology Premiere would be all about speed. Held on June 13 atop Nob Hill at the iconic Fairmont San Francisco, the event pelted a roomful of press and analysts with a rapid-fire barrage of impactful announcements. After an hour and a half, I had fifty-six photos, a dozen tweets, five pages of notes, and a nearly dead phone battery. (I noticed the in-seat power outlets only after I stood up to head to the next session.)
The 90-minute general session is available in full on AMD’s website, and there’s no real downtime that merits fast-forwarding. Sure, there’s a slick opening video offering different takes on the together we advance slogan, but it’s only 45 seconds long, and then without an introduction – no “And now…!”, no name drop, no “Hi, I’m Lisa” – AMD CEO Lisa Su claimed the stage, dispatched with pleasantries, and took off running.
“At AMD, we’re focused on pushing the envelope in high-performance and adaptive computing, to create solutions to the world’s most important challenges,” Su opened, kicking off a tour of what she called “the industry’s broadest portfolio,” citing AMD’s Instinct GPU accelerators, FPGAs, adaptive SoCs, SmartNICs, and DPUs, in addition to its Epyc CPUs, “the highest-performing processors available.”
Su started in with the CPUs, and before getting to anything new, she recapped AMD’s position with the fourth-gen Epyc “Genoa” processor, introduced in November 2012. Anyone following HPC has seen AMD’s performance claims with Genoa, but this update brought a new emphasis on cloud. “Epyc is now the industry standard in cloud,” Su claimed. “Every major cloud provider has deployed Epyc for their internal workloads as well as their customer-facing instances.”
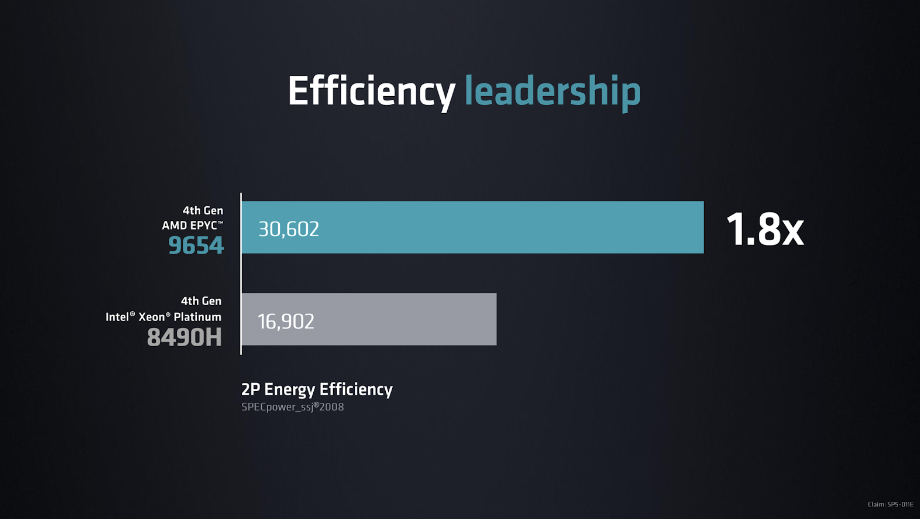
AMD also repeated its power efficiency claims with Genoa, citing 1.8x performance-per-watt advantage over comparable Intel CPUs. “Yes, we want leadership performance, but we must have best-in-class energy efficiency, and that’s what fourth-gen Epyc does,” Su said. “Genoa is by far the best choice for anyone who cares about sustainability.”
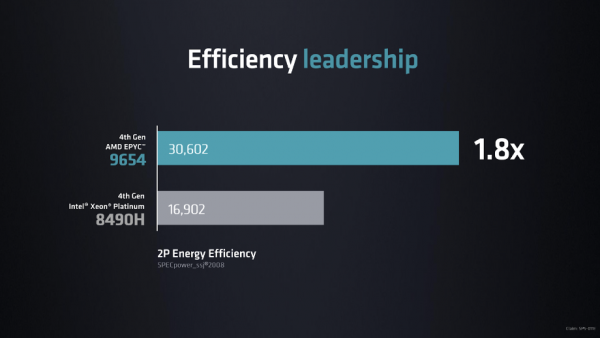 Image courtesy of AMD.
Image courtesy of AMD.
Underscoring these benefits, Su was joined onstage by Dave Brown, VP of EC2 at AWS, who announced the preview of a new M7a instance type based on Genoa, with up to 50% more performance than the previous M6a. “M7a has been designed to provide the best x86 performance and price/performance per vCPU, within the general-purpose instance family,” Brown said. “We think workloads – including financial applications, application servers, video transcoding, simulation modeling – they will all benefit from the M7a instance.”
CPUs – Bergamo and Genoa-X
All that happened before the session was 15 minutes old, and AMD hadn’t introduced anything new yet. That was about to change.
First came a new version of the fourth-generation Epyc, AMD EPYC 97X4 processors, formerly (and still colloquially) codenamed “Bergamo,” targeting cloud-native computing environments. (Even AMD executives are inconsistent as to whether the accent is on the first or second syllable of Bergamo, more like Buffalo or Bambino; Su prefers the former.)
Bergamo is built on new Zen 4c cores – 128 of them – in a core-plus-L2 chip that is 35% smaller than Zen 4, optimizing for density and performance-per-watt. The primary target market is hyperscale companies and cloud-native computing, and Su fired off another salvo of benchmarks (“Up to 2.6x more performance … up to 2.1x container density per server … up to 2.0x the efficiency …”) to claim the territory.
“Meta and AMD have been collaborating on Epyc server design since 2019,” said Alexis Björlin, VP of Infrastructure at Meta. “We’ve deployed hundreds of thousands of AMD servers in production. … Over the years AMD has consistently delivered, … and we’ve learned we can completely rely on AMD.” Björlin said Bergamo was delivering “on the order of two-and-a-half times” the performance of Milan for Meta.
Su then yielded the stage to Dan McNamara, SVP & GM of the Server Business Unit at AMD, to unveil another new version of Genoa, focused on technical computing. The “Genoa-X” processor boosts performance with the introduction of AMD 3D V-Cache technology, available in 16-core (Epyc 9184X), 32-core (Epyc 9384X), and 96-core (Epyc 9684X) versions. In another flurry of benchmarks, AMD claimed 1.8x to 2.0x performance advantage over Intel Xeon CPUs with the same number of cores.
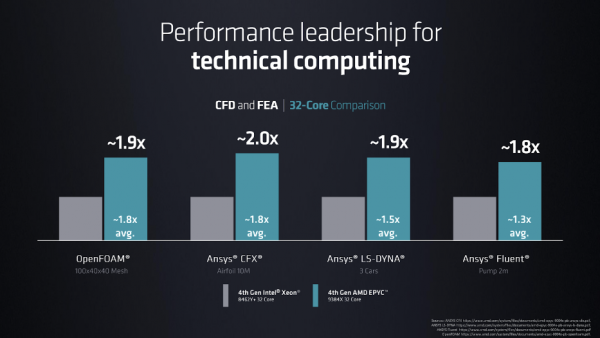 Image courtesy of AMD.
Image courtesy of AMD.
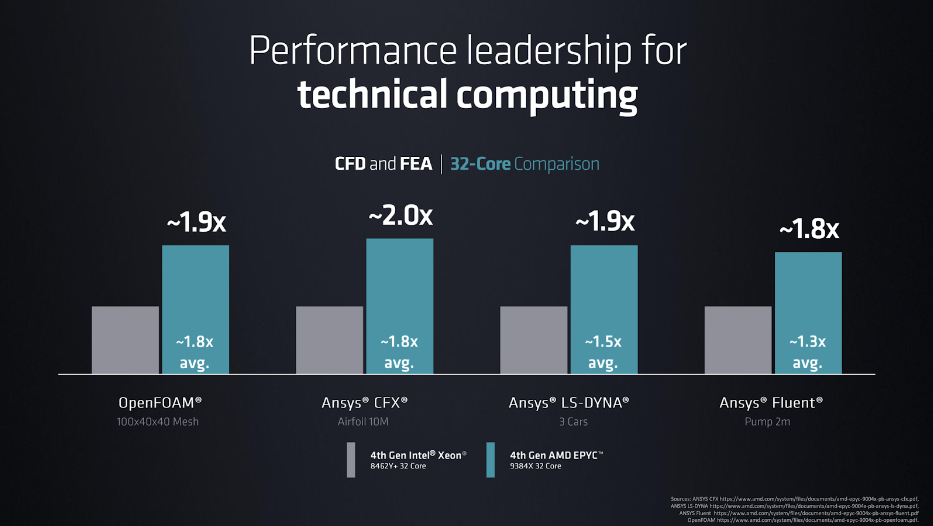
“We first introduced this technology last year with Milan-X,” said McNamara, “and now we bring it to fourth-gen Epyc, pairing it with the high-performance Zen 4 core.” The top-bin, 96-core Genoa-X offers over 1.1GB of L3 cache; the 16-core and 32-core varieties each have 768MB. “While Genoa is the fastest general-purpose server processor in the market, Genoa-X takes this performance to a new level for technical computing,” said McNamara.
Genoa-X came with a cloud announcement as well, as Microsoft Azure introduced two new instance types, both using 3D V-Cache. Comparing previous Milan and Milan-X HBv3 instances, Nidhi Chappell, GM of Azure HPC, said, 3D V-Cache “provides eighty percent more performance for our customers, at no additional cost.”
“Today we are announcing the general availability of the fourth generation of our HB series [HBv4], and along with that, we have a new, memory-optimized HPC virtual machine, which we are calling the Azure HX series,” said Chappell. “Both the HBv4 and the HX feature the 3D V-Cache.”
The main difference between the HBv4 and HX instances is the amount of configured cache, with HX offering up to 1.4TB of system cache. Most HPC application benchmarks showed a 1.6x to 2.7x improvement on HBv4 or HX relative to HBv3, but some offered much more, depending on their ability to leverage the cache. NASTRAN was the highest improvement on the chart, at 5.7x.
 Microsoft Azure’s Nidhi Chappell discusses the performance benefits of 3D V-Cache with AMD’s Dan McNamara.
Microsoft Azure’s Nidhi Chappell discusses the performance benefits of 3D V-Cache with AMD’s Dan McNamara.

Although this event did not touch on it, McNamara closed by saying, “Our final piece of the Zen 4 portfolio is Siena, which is optimized for telco and edge workloads. Siena will deliver maximum performance and energy efficiency in a cost-optimized package.” McNamara promised a future update on Siena, with the product coming to market “in the second half of the year.”
DPUs – Pensando and Smart Switch
Whew, that was a lot of news, but we weren’t yet halfway into AMD’s “industry’s broadest portfolio.” Next up was Forrest Norrod, EVP and GM of the Data Center Solutions Business Group, to discuss AMD’s networking solutions, built upon last year’s acquisition of Pensando. “Beyond the CPU, the workload-optimized datacenter needs to be one where every high-value workload is supported by high-performance engines, is energy-efficient, and is agile, meaning it is easy to deploy, manage, and secure,” said Norrod. “That’s our vision of the datacenter.”
Norrod touched on the importance of AMD’s Solarflare NIC and SmartNIC solutions, courtesy of its acquisition of Xilinx, but the new action was in the Pensando portfolio. AMD improved the programmability of the P4 DPU with the announcement of the AMD Pensando Software-in-Silicon Developer Kit (SSDK).
“AMD and our Pensando team evolved the concept of the DPU beyond a sea of cores to the world’s most intelligent data flow processor,” said Norrod.
Norrod also affirmed that the AMD Pensando P4 DPU is available to be deployed as a SmartNIC (coincidentally, the SmartNICs Summit was being held simultaneously less than fifty miles away, at the somewhat less showy DoubleTree by Hilton near San José airport). The P4 DPU Offload functionality can be brought to existing network switches, Norrod said, and AMD also has partnered with HPE Aruba Networking to build a Smart Switch around the AMD Pensando P4 DPU, targeting on-premises enterprise deployments, to provide “not just better efficiency, but enhanced security and observability,” both in the datacenter and in edge computing environments. Norrod said the next-generation DPU, codenamed “Giglio,” would be available by the end of the year.
AI – Software Ecosystem
In discussing AMD’s investments in AI, Su invoked the Frontier and LUMI supercomputers for the first time, reminding us that AMD CPUs and GPUs are at the heart of two of the top three systems on the Top500 list. Naturally, a lot of AI research and work on frameworks will come from these leading systems. But when it comes to generative AI, there is a broad software ecosystem that extends to a wide community.
AMD President Victor Peng addressed this challenge in his segment. “I can sum up our direction … with three words: open, proven, and ready,” he said. “While this is a journey, we’ve made really great progress in building a powerful software stack that works with the open ecosystem of models, frameworks, libraries, and tools.”
Peng gave an updated overview of the AMD ROCm optimized AI software stack, which he called “a complete set of libraries, runtimes, compilers, and tools needed to develop, run, and tune AI models and algorithms.” But the audience sat up more when he introduced a pair of guest partners: PyTorch co-founder (and current Meta VP) Soumith Chintala and Hugging Face CEO Clement Delangue.
Chintala said a major benefit of PyTorch’s collaboration with AMD was portability. “We have a single dominating vendor,” he said, alluding to Nvidia. Due to the joint effort between PyTorch and AMD with ROCm, he said, “you don’t have to do much work, almost no work in a lot of cases, to go from one platform to the other. … It’s like super-seamless.”
 AMD President Victor Peng and Hugging Face CEO Clement Delangue announced their new partnership.
AMD President Victor Peng and Hugging Face CEO Clement Delangue announced their new partnership.

Peng announced that AMD had just formalized a relationship with Hugging Face. “Hugging Face is lucky to have become the most-used open platform for AI,” said Delangue, citing a repository of over 500,000 open models. “Over 5,000 new models were added just last week,” he claimed. “We will optimize all of that for AMD platforms.”
GPUs – MI300A and MI300X
With the event in its final 15 minutes, Su returned to the stage, for perhaps the most critical announcements of the event. “We always like to save hardware for last,” Su quipped, before noting, “Generative AI and large language models have changed the landscape. The need for more compute is growing exponentially.”
At CES 2023 in January, AMD had already previewed its MI300A APU, based on the latest CDNA3 architecture, featuring 128GB of HBM3 memory, with shared-memory capabilities linking CPU and GPU. Su announced that the MI300A, which will power the El Capitan supercomputer at Lawrence Livermore National Laboratory, is sampling now.
The MI300A is based on a chiplet design, which Su cited as critical for the final big announcement. “With our chiplet construction, we can actually replace the three Zen 4 CPU chiplets with two additional CDNA3 chiplets to create a GPU-only version,” Su said. “We call this MI300X.”
The MI300X has even more HBM3 memory than the MI300A, up to 192GB, with 5.2TB/sec of memory bandwidth, claiming a 2.4x advantage in HBM density and 1.6x advantage in HBM bandwidth over Nvidia H100. Su said the focus on memory capacity and speed is in-line with the requirements for training large language models (LLMs). “We truly designed this product for generative AI,” she said.
 AMD CEO Lisa Su holding the new MI300X.
AMD CEO Lisa Su holding the new MI300X.

Su showed off the capabilities of the new MI300X in a live demo, running an LLM called Falcon – currently the most-popular model on Hugging Face – on a single GPU. Given the prompt, “Write me a poem about San Francisco,” Falcon took about 20 seconds to generate ten lines of truly awful free verse (sample: “The city of dreams that always keeps you yearning for more!”), though the quality of the “poetry” hardly dampened the excitement around the potential.
Su emphasized that the HBM capacity allowed Falcon to run entirely in memory on a single GPU, extrapolating to other commonly used AI models. “If you just look using FP16 inferencing, a single MI300X can run models up to approximately 80 billion parameters,” Su boasted, to the crowd’s applause. “Model sizes are getting much larger. … With MI300X, you can reduce the number of GPUs.”
And Su still wasn’t done. I don’t think I’d ever before seen a major product announcement come within the final three minutes of a keynote session, but I was about to, as Su announced the AMD Instinct Platform, an OCP-compliant form factor packing eight MI300X modules and 1.5TB of HMB3 memory. By leveraging OCP, Su said, AMD is “making it really easy to deploy MI300X into existing AI rack and server infrastructure.” AMD expects both the MI300X and the AMD Instinct Platform will begin sampling in Q3, with production ramping up by the end of the year.
 Image courtesy of AMD.
Image courtesy of AMD.

The Race is On
Ever since the introduction of the Zen architecture, AMD has continued to impress with a regular cadence of product launches and upgrades, consistently showing progress and meeting its objectives. To be sure, AMD is coming from behind on two fronts, as the CPU space has been dominated by Intel for decades, and Nvidia has enjoyed a near-total monopoly in the GPU arena.
As AMD releases new products, the company seems to be aware that the war is fought in software, and again there is work to be done in the AMD ecosystem around ROCm. The aegis of the national labs will help, particularly in HPC-adjacent fields, but the big money is in hyperscale, and it was no accident that the featured AMD partners at this launch event included AWS, Microsoft Azure, and Meta.
For all the benchmarks targeting Intel, it seemed like the primary competitive target of the day was Nvidia. If AMD can make significant inroads with the hyperscalers’ AI infrastructure, opening models beyond the CUDA walled garden, this could become a very competitive race for the future of datacenter infrastructure, both on-premises and in the cloud. Judging from this launch event, AMD does like to race.